At the NHS, we view APIs as services
Technology in government • Friday March 06, 2020 @ 11:16 • 4 days ago
The Government Digital Service (GDS) Service Manual includes plenty of guidance on agile software delivery, including details of the specific phases of an agile project. Initially it’s not obvious how these phases should apply to delivering APIs. With a bit of interpretation the phases do fit quite well, but this relies on having strong experience in developing APIs.
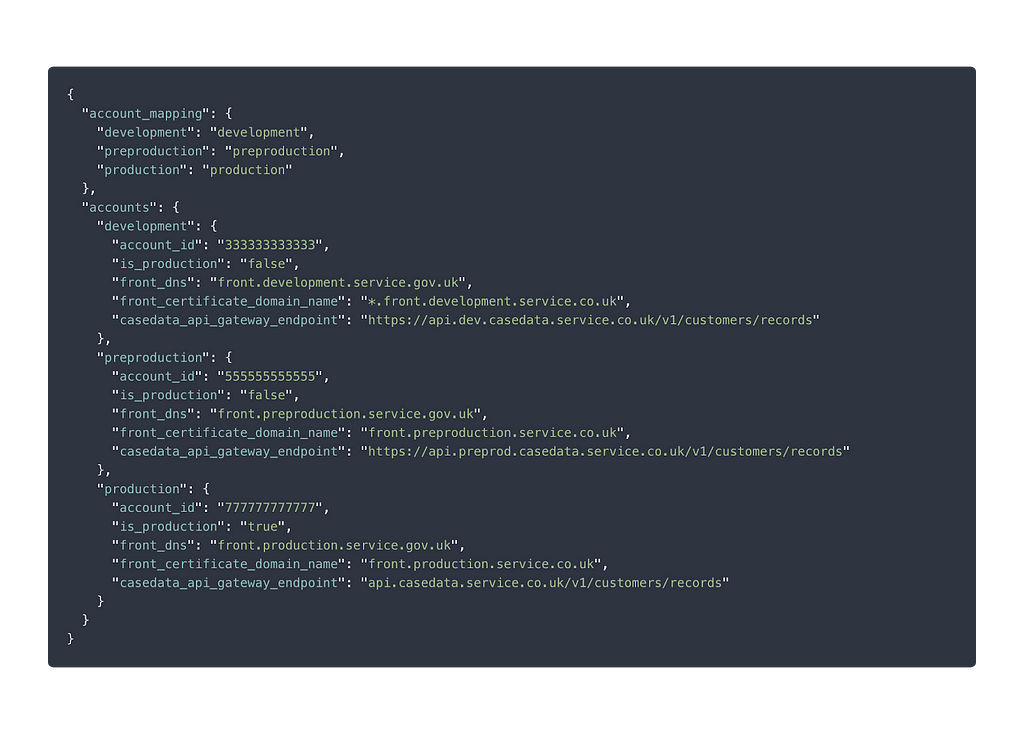
NHS Digital is working with GDS, HMRC and DWP to produce some guidance for API delivery teams to sit on GOV.UK. This is intended to help teams delivering APIs make sure they meet user needs.
Publishing API delivery guidance on GOV.UK
In the latest refresh of the Service Standard, there’s a lot of focus on thinking more holistically about government services. That’s a really positive step. Delivery teams are now being challenged to make sure their online service works seamlessly with other channels such as phone, paper and face to face. An API is another of those channels, but it’s also a service in itself.
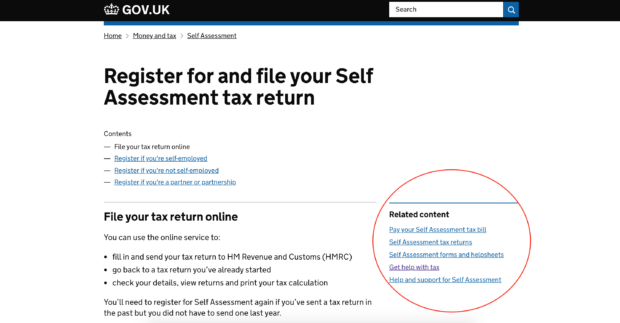
More and more teams are building APIs, often allowing citizens to interact with government services using third-party software. For example, citizens and accountants can submit tax returns via HMRC APIs directly from their accountancy software.
APIs also allow government services to be incorporated into apps which do other things. In some cases, an API might be the main or only channel into a government service. This is true of HMRC’s Making Tax Digital for VAT service, and also for many of NHS Digital’s national healthcare services.
Often APIs are actually the services themselves. For example, GOV.UK Notify and GOV.UK Pay are both well known APIs that serve government users to help them transform citizen-facing services. Both APIs have gone through Service Assessments, and the reports are openly available. For instance, the Notify Beta Assessment is here on GOV.UK.
Adding guidance on API agile delivery to GOV.UK will recognise that APIs are services too. It’ll also recognise that agile API delivery teams need different skills than teams working on citizen-facing services, and may need to focus on different areas.
For example, agile API delivery teams may need:
- technically-minded user researchers to engage with software developers and end users
- technical writers to produce API documentation and understand how to write for a technical audience, instead of a content designer working on online services content for end-users
- API designers, such as an experienced developer or an architect with an understanding of the OpenAPI spec
These teams may also need a product owner, who might also own the online channel.
Meeting the needs of APIs users
Since its creation, a key aim of GDS has been to encourage delivery teams to engage more with users - to understand their needs, test new services with users and to iterate those services until they work really well. Teams delivering online services now have user researchers, service designers, interaction designers, content designers, and technical writers as standard.
This user needs-first approach doesn’t seem to have been bedded in so well with teams delivering APIs yet. It’s common to come across API teams that haven’t done any user research, and it’s easy to see why. APIs are not intended to be used directly by people - they are used by other systems. However, APIs still have users.
Users of APIs generally fall into 3 categories:
- Government users, for example software developers or technical architects, who understand the government context and who are using government APIs within their services.
- Third-party users, usually software developers, who need to design, build, test, and run the software that uses a government API, and who may be working with government APIs for the first time.
- End users of the third-party software, who need to use the complete service via that third-party software.
It’s important for teams delivering APIs to engage with these user groups, rather than assume they know what the API should do, build it, deliver it, and then move on to something else. Research to understand API users' needs can improve the design substantially, while reducing the time and cost of integration.
For example, NHS Digital recently conducted a survey of healthcare software developers. The average rating for ease of integration with NHS Digital APIs was 2 out of 5.
Common pain points included:
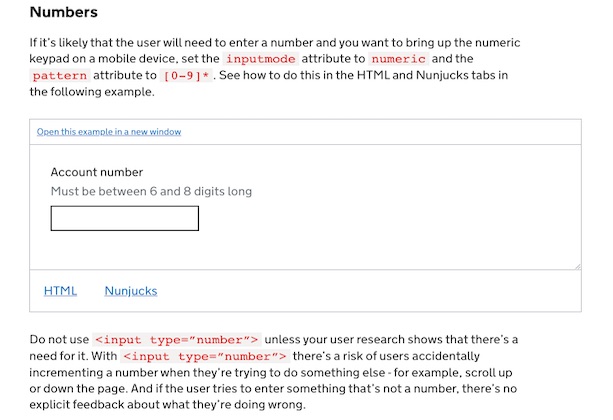
- hard to find, poorly written, incomplete, or inconsistent API documentation
- APIs which were technically complex and hard to integrate with
- hard to access or not useful test environments
- labour-intensive or convoluted assurance processes
- hard to find and slow help and support
Drafting the guidance
We’re looking for API delivery teams from across government to get involved in this work. We’re hosting a workshop on 24 April with the API and Data Exchange Community of Practice to discuss the guidance we’ve been working on with GDS, HMRC and DWP.
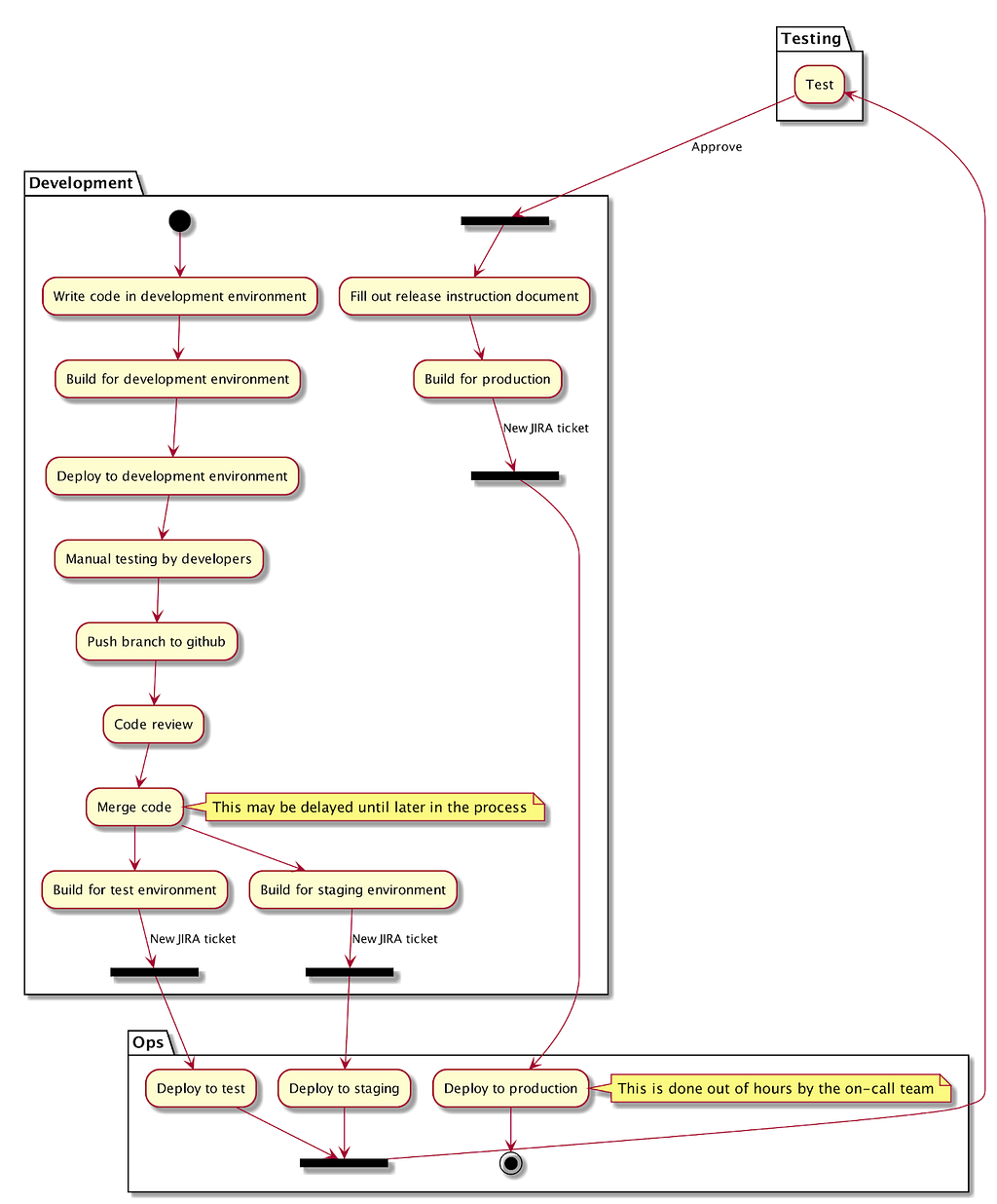
At the basic level, our understanding of API delivery looks like this:
- Discovery: similar to online services, you must define the problem, understand the opportunity, and find users (software developers and end users)
- Alpha: prototype different API specifications and, possibly, a callable sandbox that software developers can test
- Beta: similar to online services, put the API into production but continue to gather feedback from software developers and their end users, especially on data quality, and iterate the service
- Live: declare the API as “stable” but continue to monitor it as usage scales up, and continue to improve it
- Retirement: more complicated for APIs than for online services because you might need to retire a version of an API if you make breaking changes, or manage multiple versions in parallel
If you want to help us add more details to our guidance, email api-data-request@digital.cabinet-office.gov.uk. If you want to attend the workshop ‘Delivering APIs to meet user needs’ on 24 April you can sign up on our Eventbrite page.